
Discord's Database Evolution: Scaling to Handle Trillions of Messages
Providing a smooth chat experience for an app with over 20 million daily active users is tough. Let's explore how Discord's database has evolved to handle this massive volume of data

Introduction
Discord, initially popular among gamers, has grown significantly, boasting 29 million daily users by 2024. A rough calculation suggests Discord handles an average of 4 million messages per minute, considering each active user sends about 200 messages daily. Let's explore Discord's journey in upgrading its database architecture.
Evolution of database infrastructure in Discord

Discord initially used MongoDB for storing chat messages. However, as the message count reached around 100 million, latency issues became a significant problem.
This led to a migration to Cassandra. The original article doesn't specify why Cassandra was chosen over improving MongoDB's design, but I speculate two main reasons.
First, Cassandra was developed by Facebook for a similar purpose—powering inbox search—with proven scalability and reliability in chat applications.
Second, Discord's team might have had more expertise with Cassandra, influencing their choice.
Migration to Cassandra
Highlights of Cassandra’s Design
These are some of the architecture highlights of Cassandra which I believe make it a very good candidate for Discord.
Fast write operation
Fast write performance: Discord showcases a balanced 50:50 read/write ratio, indicating a high demand for write capabilities. Cassandra, known for its excellent write performance, is well-suited for such requirements.
Benchmark Data: Comparisons on similar hardware show Cassandra outperforming MySQL in write speed (Cassandra: 2.9ms, MySQL: 16.5ms), though it has slower read times (Cassandra: 38.8ms, MySQL: 2.3ms). [2]
Linear Scalability
Peer-to-Peer Architecture: Cassandra's design eliminates the need for a central leader node. Each node can independently handle requests, facilitating seamless scaling.
Ease of Scaling: Adding more nodes to a Cassandra cluster straightforwardly increases its capacity for handling more read/write operations.
Notable Implementations: Netflix and Apple exemplify Cassandra's scalability, with Netflix managing 300,000 nodes for 100 petabytes of data and Apple using 22,000 nodes for 12 petabytes as of 2022. [3]
Decentralised architecture and high availability
No Single Point of Failure: Every node in the cluster can serve both read and write operations, which means the failure of a single node doesn't render the system inoperable.
Self-Healing: Cassandra uses a gossip protocol to constantly exchange state information about itself and other nodes to quickly detect when a node goes down and automatically reroute traffic to available nodes.
Read Write operation in Cassandra
Let's dive deeper into how read/write operation works in Cassandra.


In Cassandra, any node can act as a coordinator for handling read and write requests. Each node maintains a map of token ranges to direct requests to the appropriate node. A token represents the partition key of a table, ensuring requests are evenly distributed across the cluster to prevent overloading any single node.
When a node receives a write request, it uses a consistent hashing algorithm to convert the partition key into a token. This token then determines which Cassandra nodes the request is forwarded to.
The success of a request is based on a configurable consistency level, N. The coordinator node waits for confirmations from N Cassandra nodes before marking a request as successful and notifying the client.
Migration to ScyllaDB
Challenges Encountered Using Cassandra
Despite the many advantages we've highlighted, Cassandra isn't without its challenges, as the Discord team has discovered during their production use. They've encountered several key issues, notably:
i. Queries that extend over multiple partitions, affecting read performance.
It's somewhat surprising to learn that chat groups with fewer messages can actually be more costly to read! This might seem counterintuitive at first, but it becomes clearer once you look into the specifics of how these queries work behind the scenes.
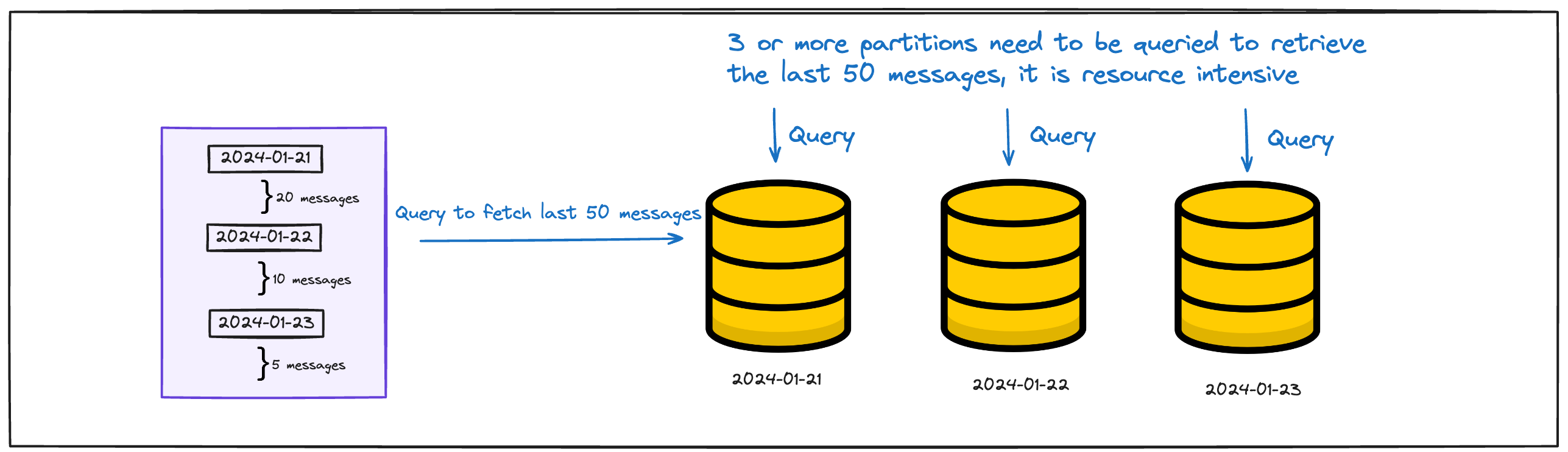
Why is read more expensive for chat group with fewer messages ?
More partitions to scan: The database for messages is organised by time into partitions. So, when a chat group has fewer messages, it means there's a need to scan through more partitions to fetch the last N messages.
Cache miss, more disk scan: As these messages are older, they're less likely to be found in the cache (MemTable) and, as a result, Cassandra has to search through multiple SSTables on disk. These disk scans are resource-intensive operations.
p/s: Cassandra uses LSM tree as its primary data structure for storing data.
ii. Frequent GC
Since Cassandra is Java-based, it uses garbage collection to recycle unused objects and free up memory.
Objects surviving many collection cycles need a full, "stop-the-world" garbage collection cycle. During this, Cassandra pauses, handling only object recycling. Users may experience increased latency or failures retrieving chat messages.
Why ScyllaDB ?
Better performance: ScyllaDB shares Cassandra's architecture but is rewritten in C++, resulting in improved performance. Benchant [2] data shows ScyllaDB outperforms Cassandra in read and write operations on similar hardware.
No FullGC: Unlike Java-based Cassandra with garbage collection (GC), ScyllaDB is C++ without built-in GC. Avoiding full GC operations mitigates latency spikes caused by Cassandra's GC pauses.
Key Architecture Upgrade
What problem does Discord face?
One key architectural issue that Discord frequently encountered was the "hot partition" problem, which significantly impacted performance. A hot partition occurs when too many requests hit a single database partition within a short period, overloading that particular database instance.
How does this usually happen?
Imagine a scenario where an admin tries to notify everyone in a group chat. This would lead to many users simultaneously accessing the same channel, reading and responding to the thread. Since messages in the same channel are routed to the same database partition, you can imagine the immense load on that particular database instance at that moment.
Data Services serving data

What are the key highlights of this architecture upgrade?
Database query batching: Instead of sending queries directly to the database, Discord implemented a batching mechanism at the service layer. For instance, if the same query is batched every second at the service layer, then 1000 queries per second for the same channel would result in only one database query per second. This approach significantly reduces the impact of hot partitions.
Efficient routing: Discord utilizes consistent hashing to route messages from the same channel to the same message service. This allows queries to the database to be batched more efficiently. Imagine if messages were routed to different message services; then multiple queries (one from each service) would be required to retrieve messages from the same channel, reducing the effectiveness of batching.
Closing Thoughts
This journey of exploring Discord's database upgrade has been truly fascinating. . Notably, some of Cassandra's design drew inspiration from Amazon's Dynamo Paper [4], which introduced concepts influencing many modern NoSQL databases. I highly recommend the Dynamo Paper [4] for a deeper understanding of the foundational ideas powering most NoSQL databases today.
Thank you for taking the time to read and support this newsletter.
If you've enjoyed what you've read, consider showing your support by clicking the ❤️ button at the bottom of this email. Even better, share it with your friends!
Reference
https://discord.com/blog/how-discord-stores-billions-of-messages
https://discord.com/blog/how-discord-stores-trillions-of-messages
https://www.bankmycell.com/blog/number-of-discord-users/#:~:text=The%20number%20of%20people%20who,40%25%20from%20the%20previous%20year.
https://benchant.com/ranking/database-ranking
https://news.ycombinator.com/from?site=twitter.com/erickramirezau
https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf